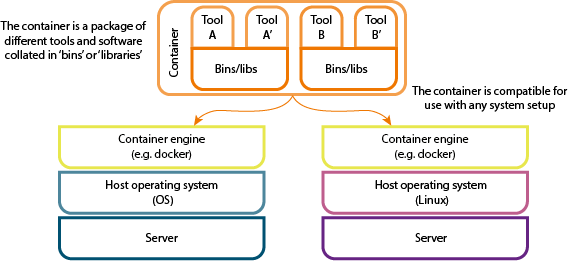
Maintaining bioinformatics infrastructures is really challenging with the current Grant schemes. Most of the time what you have ahead for your software are the following plans: bug fixing, documentation, user support, refactoring to make the software faster or compatible with different platforms or architectures... This is almost impossible to be sold by itself in a grant proposal. It needs to be blur or hidden in the proposal with new improvements, data support or data analysis.. probably with new ideas that the developer and the PI don't even try before. But still, you need to get the grant.

In summary, the bioinformatics community is struggling to get money to maintain and support bioinformatics software and databases. Different initiatives and grant calls have been created in recent years to support and sustain the bioinformatics open-source community. But, they have encouraged the creation of "new/novel" things rather than support the development of well-established tools. And here, is when Mark and the Chan Zuckerberg Initiative succeed today.
The Chan Zuckerberg Initiative (CZI) announced the final list of bioinformatics open-source projects awarded with the CZI’s Grant. After reading the final list, it was clear to me that this group of reviewers really knows what they are doing and the CZI is really pushing forward to maintain bioinformatics infrastructures and software.
The Chan Zuckerberg Initiative (CZI) announced the final list of bioinformatics open-source projects awarded with the CZI’s Grant. After reading the final list, it was clear to me that this group of reviewers really knows what they are doing and the CZI is really pushing forward to maintain bioinformatics infrastructures and software.